
 As evidence-based practice is becoming a staple in physical therapy education, it is important we properly assess each piece of research before choosing whether or not to incorporate its findings into our practice. Given the breadth of science courses that consume most of our schooling, non-clinical classes like evidence-based practice often get set aside as less important. Unfortunately, we often fail to realize the significance of search strategies, article assessments, and more when we are in the didactic portion of school. Instead, this material should really be one of the largest emphases in our programs, due to the need to stay up to date with best practice methods. With the NPTE and clinical work coming up soon, we thought it would be a great time to review some of the core components of EBP. This review is by no means exhaustive, but instead is intended to give you a foundation for further review. Question Development/Performing the Search We start with a question: background or foreground. Background questions are exactly what they sound like, in that we are searching for additional information regarding a patient's pathology or need. Foreground questions, on the other hand, are directed more towards management of the patient's problem. They often contain 4 components: -patient/client details such as age, gender, diagnosis, etc. -a specific diagnostic test, clinical measure, treatment, etc. -a comparison test, predictive factor, outcome, etc. -the consequence of interest This is frequently referred to as a PICO statement. P refers to information regarding patient details (i.e. elderly patients with RA). I refers to the intervention, diagnostic test, or whatever is being studied. C is the test, interventions, etc. to which the study is comparing (this element is not always necessary). O refers to the outcomes sought (pain scores, quality of life, strength, etc.). Now that the PICO statement is formed, we are ready to input the information from the PICO statement into the search engine. There are more than a few search engines out there, so we will only review the main features of a few of them. First, it's important to know a few components of search engines. MeSH terms are words/phrases that contain information for a pathology/treatment/etc. and allow the user to obtain information that may use different terminology for the same concept. For non-MeSH terms, it's important to included synonyms in order to expand your search. After inputting your information from the PICO statement and performing a search, check to see if MeSH terms were available for your search (if applicable). This may improve your findings. Also, not every search engine follows the same rules for boolean operators (i.e. AND/OR), so be sure to figure out how that particular one utilizes the operators. One of the most commonly used search engines is PubMed. It utilizes the above-mentioned MeSH terms and allows the user to implement limits on areas like publication date, type of study, language, etc. The Clinical Queries function allows a more tailored search for studies pertaining to etiology, diagnosis, prognosis, therapy, or CPRs. It can automatically search for the best research design. One of the most useful components of PubMed is "My NCBI." By making a (free) account with PubMed, your search parameters for a topic can be saved and routinely run. The results of any new studies that match that search are then emailed to you. This is an excellent way to stay current with new evidence! CINAHL is similar to PubMed in many areas, but it includes additional studies that do not meet PubMed's inclusion criteria. Unfortunately, CINAHL requires a subscription (and has since changed names to EBSCOHost). While this search engine does not utilize MeSH terms, it does have a vocabulary system with the same general functionality. Cochrane Library contains six databases and registries: Cochrane Reviews (systematic reviews and meta-analyses by Cochrane Collaboration), Other Reviews (systematic reviews and meta-analyses by non-Cochrane Collaboration), Clinical Trials (individual RCT performed by other investigators), Methods Studies, Technology Assesments, and Economic Evaluations. It utilizes MeSH terms, but has decreased limitation and expansion of searches functionality. PEDro is a free physical therapy-focused search engine that contains RCTs, systematic reviews, and CPRs in physical therapy. Studies are rated on a 0-10 scale based on their internal validity and statistical interpretability. Hooked on Evidence is a free database of citations for physical therapy interventions based on the pathology. Four criteria must be met to be included in this database: human subjects, at least one physical therapy intervention, at least one outcome measure of the intervention, and published in an indexed English-language peer-reviewed journal. Articles are organized according to research design type (RCTs listed first). There are other search engines out there, but these are some of the more common ones seen.
Analyzing the Search Results One thing we definitely need to consider is the type of study. The research design has an impact on bias contributions, applicability to larger populations, and more. According to Jewell, the hierarchy of evidence is: -1a. Systematic Review of RCTs that do not have a statistically significant variation in the direction or degrees of results -1b. Individual RCT with a narrow confidence interval -1c. All or None Study (a study in which some or all patients died before treatment became available, now none die - think a vaccine) -2a. Systematic Review of Cohort Studies that do not have a statistically significant variation in the direction or degrees of results (cohort refers to a group of individuals followed over time that sometimes have a similar characteristic) -2b. Individual Cohort Study (including low-quality RCT) -2c. Outcomes Research -3a. Systematic Review of Case-Control Studies that do not have a statistically significant variation in the direction or degrees of results (a retrospective approach when subjects known to have the outcome are compared to those without) -3b. Individual Case-Control Study -4. Case-Series Study; Cohort or Case-Control Study that did not: define comparison groups adequately or did not measure exposures and outcomes objectively or in a blinded fashion or control for confounders or have sufficient follow-up -5. Expert Opinion without explicit critical appraisal, or based on physiology, bench research or "first principles" While this hierarchy can aide in selection of evidence, we should still read and fully evaluate articles before implementing them into practice. The reason is because a high-level article, such as a systematic review, may have included poor methods: ignoring confounding variables, limited blinding, poor experience of clinicians, etc. There are many items to consider when reviewing evidence. One place that can sometimes be good to start is a literature review, because it often reviews the research up until that point of time. Things to look out for, however, include evidence being judged by date of publication, flow of article, and relation between articles selected and review topic. Each can potentially lead to eliminating useful information. Older studies may still have the best quality of evidence. Sometimes seemingly unrelated articles contain information that is actually very connected to the study. Another quality of studies not mentioned was a meta-analysis. Systematic reviews with meta-analysis incorporate summaries of the primary studies that are critically appraised and statistically combined. The result is an even higher level of evidence. Research design refers to how the study is carried out. In experimental studies, some of the subjects are manipulated with a treatment/intervention (independent variable) in order to study the effect (dependent variable). Experimental studies can have 3 variations for the control group: no treatment, placebo, or both groups get standard treatment but experimental group gets additional interventions. Quasi-experimental studies are similar in that they involve manipulation again, but either lack a second group for comparison or random assignment. There are a few methods for quasi-experimental studies: time series format (repeated measures collected over time before/after experimental intervention is introduced to a single group), non-equivalent group (similar to experimental but no random assignment), single system (one subject undergoes experimental treatment and control treatment periods in alternating fashion), and a few others. In single-system/subject designs, some common methods are A-B, A-B-A, and A-B-A-B formats. "A" refers to baseline and "B" refers to treatment. Non-experimental studies obviously are purely observational. A within-subjects study occurs when the outcome is repeatedly measured in a single group of subjects. Between-subjects refers to outcomes being compared between 2+ groups. Bias can occur in a variety of points in a study: subject recruitment/assignment/communication, calibration/use of equipment, maintenance of environmental condition, and more. It can be minimized with random assignment of subjects and masking of subjects and investigators (if both are blinded, it is referred to as a double-blind study). You may notice some time descriptors for studies as well. Cross-sectional refers to data being collected once during a single point in time. Longitudinal refers to repeated measures over an extended period of time. Retrospective is historical and obviously lacks randomization. Prospective is data being collected in real time. There are many other factors to consider when analyzing the methodological quality of evidence. Inclusion/exclusion criteria can render an otherwise well-performed study useless. We recently did a review of the Joint Line Fullness Test for meniscal injuries. While the results of the study looked promising, the researchers exluded any patients with an acute injury (within 6 weeks of exam) or presence of osteophytes, joint space loss, or arthritis. These are typically the types of patients we see in the clinic, so it doesn't really matter how accurate the test is in other conditions. We should also take note as to whether or not the inclusion/exclusion criteria is even appropriate based on the clinical question. Look at to see if participants were lost during the study (attrition), why they were lost, and if any adjustments were made in the statistical analysis. Consider how many databases/resources were used for the study. After reviewing the various search engines, it should be evident that one database doesn't contain all the information. In systematic reviews, the number of individuals reviewing research studies (and whether or not they were blinded) may impact their findings.
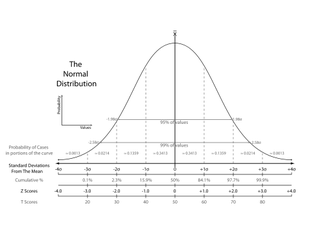
Many experimental studies start off with a null hypothesis that is the common understanding at the time (therapeutic exercise = therapeutic exercise + manual therapy). The researchers develop an alternative hypothesis to challenge what is currently accepted (therapeutic exercise < therapeutic exercise + manual therapy). Tests of significance can be used to determine if any differences found in the groups are true or are due to chance. If they are true, then they may be applicable to the population. The alpha level is first set to determine the level of probability that results are not due to chance. The most common ones are .05 or .01. If the p-value is below these, there is a 5% chance that the differences in the study were due to chance (alpha level 5). Results that are "statistically significant" represent heterogeneity. If there is overlap of confidence intervals or the p-value is not below the alpha level, homogeneity is present. As with any study, there lies the risk of error at some point during the process. Type I error refers to the null hypothesis being rejected when it shouldn't have been. Type II error occurs when the null hypothesis should have been rejected when it wasn't. A t-test can be used to compare 2 different groups. It can be either one-tailed or two-tailed. One-tailed only assess one end of the population distribution. Two-tailed assesses both ends. Any time more than 3 groups need to be assessed for variance, ANOVA (analysis of variance) should be utilized. Simple ANOVAs compare only 1 variable between groups, while factorial ANOVAs compare multiple variables between groups. ANCOVA compares multiple treatment groups, while controlling for any other variables that might affect the results. T-tests, ANOVAs, and ANCOVAs are referred to as parametric tests in that they are based on the population. The calculations result in the previously described p-value to determine if the findings are statistically significant. For non-parametric tests, we can use the Chi square test. It compares actual frequencies to expected and is followed up with a p-value to again determine the likelihood that the results are true, instead of being due to chance. Some values that are regularly reported for examination techniques include sensitivity, specificity, positive/negative likelihood ratios and positive/negative predictive values. Sensitivity refers to a test's ability to accurately rule out a disease and is scored between 0 and 1.00. Tests with high Sensitivity, rule Out a disease (SnOut). Specificity refers to a test's ability to accurately rule in a disease and is scored between 0 and 1.00. Tests with high Specificity, rule In a disease (SpIn). Positive and negative likelihood ratios work in a similar way but are not limited to numbers between 0 and 1.00. They act more as "persuasive information" and are more individualized than sensitivity and specificity(Jewell, 2010). Clinicians are required to determine a patient's pretest probability, then incorporate the likelihood ratio for the test and determine how "likely" the patient has the pathology. Predictive values are used to determine the true positives (or negatives) out of those that tested positive (or negative), both true and false. Another common statistic we'll see is correlational research. These studies look to see how well two variables are related to each other; they do not signify causation. The numbers are expressed between -1.00 to 1.00. When near zero, there is a low correlation/relationship. When near 1.00 or -1.00 there is a strong relationship. Positive refers to direct correlations, while negative refers to inverse correlations. This may be referred to as "Pearson's r" for two groups or "Intraclass Correlation Coefficient (ICC)"6 for 3 or more groups. These values can be used to assess the reliability of examination techniques as well. Intra-rater reliability refers to the ability of an individual to consistently obtain the same findings given the same variables. Inter-rater reliability refers to the ability of different individuals to obtain the same findings given the same variables. 
As you can see there is a lot to remember when it comes to appraising evidence. Hopefully, you found this review useful for a foundation in your studies and the practice of utilizing evidence, but this does not by any means encompass everything. If you need further information for statistical analyses and research design, we recommend reviewing your notes and text books. Most of the information discussed in this review is from Jewell's Guide to Evidence-Based Physical Therapist Practice. Reference:
Jewell, Dianne. Guide to Evidence-Based Physical Therapist Practice. Sudbury, MA: Jones & Bartlett Learning 2011. Print.
0 Comments
Leave a Reply. |



 RSS Feed
RSS Feed